
Introduction – The Layers of AI
The most important and exciting investment question right now is: ‘which parts of the AI stack will accrue the most value?’
To date, this has involved a lot of guess-work, but as the applications and limitations of AI become clearer, we’re moving from guessing to having an informed view on how the battle may play-out.
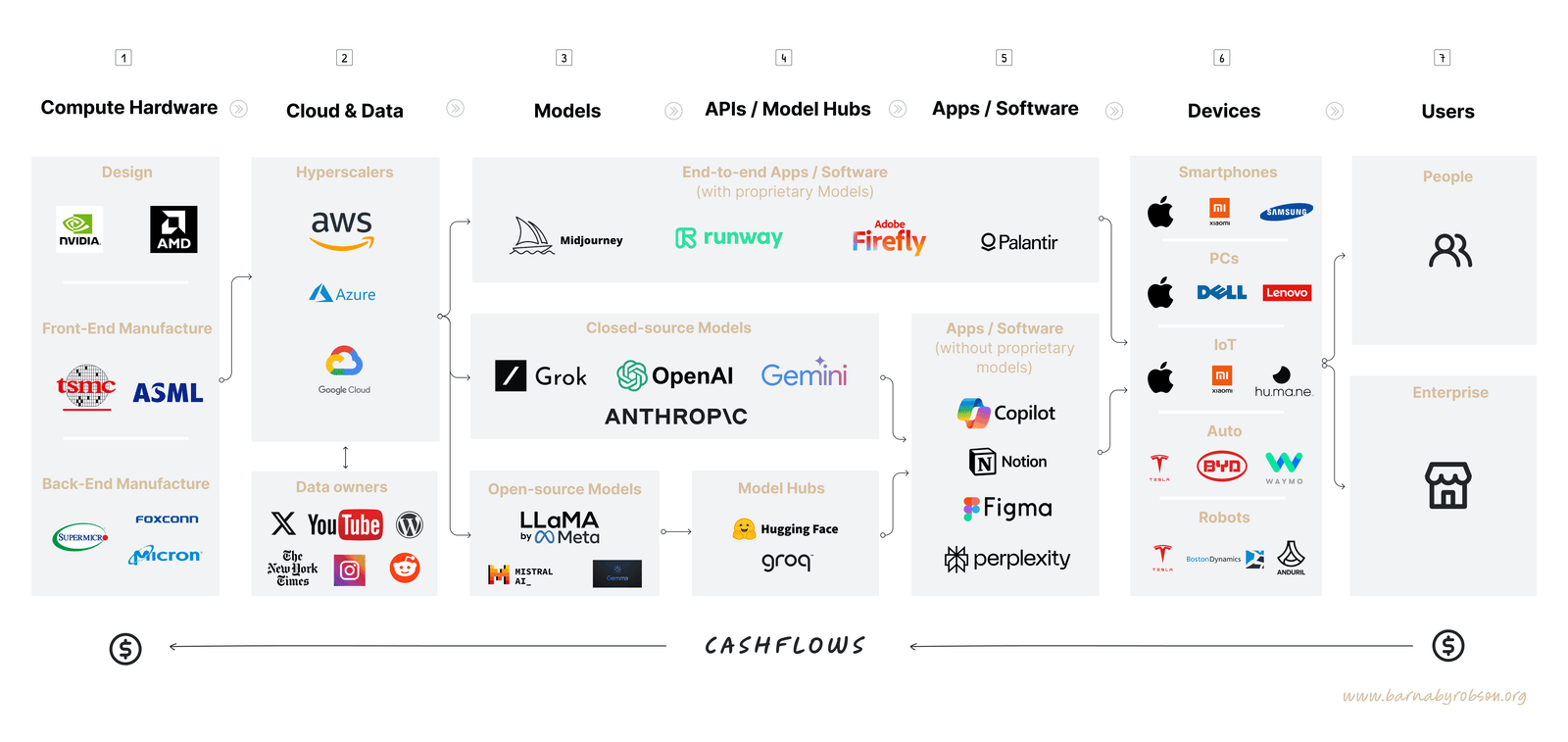
To start with – here’s how I see the AI value stack. I.e. 7 layers for potential value accrual:
- Compute Hardware – This is the foundational layer, providing the necessary processing power that all AI systems rely on. It’s the hardware that drives everything else.
- Cloud & Data – Most of the AI compute is housed in the cloud by the ‘Hyperscalers’ – the mega cloud companies that provide vast infrastructure for large-scale data processing and storage. Data access is also crucial as it feeds the system with information to train on and for ‘inference’ – the process of running live data through a trained AI model to make a prediction or solve a task.
- Models – At this layer, specific AI Large Language Models (LLMs) are developed. These are the algorithms designed for various tasks, from image recognition to language processing. Some of the LLMs have their code open-sourced (e.g. Llama), while others are Closed (e.g. OpenAI).
- APIs / Model Hubs – This is the process by which applications and developers can gain access to models – either closed or open ones. For example, Hugging Face provides a library of opensource models which can be downloaded and run locally. Groq hosts OpenSource models in its cloud and provides API access to developers. There are lots of other building blocks and services that sit in this layer offering the environments and utilities necessary for creating and managing AI models.
- Applications / Software – This is where AI models are applied to solve real-world problems, turning potential into actual utility.
- Devices – These are the physical devices by which people access AI – mostly through Smartphones and PCs at this point – but some manufacturers are developing specialist AI devices (e.g. Humane). We’re also see growing confidence in autonomous vehicles and advanced robotics.
- Users – Ultimately, the value of AI is determined at this layer by how it is adopted, used, and perceived by end-users, whether they are businesses or consumers. Users should get real value from AI, otherwise they will not pay for it.
A mapping with example leading companies across each layer is set out below.
Understanding the competitive landscape
Using these layers and how they interact helps in identifying where the competitive friction lies between the MegaCaps and emerging AI players, and how the chessboard may be played. For example:
- OpenAI is burning capital buying Compute Hardware, so Sam Altman (CEO of OpenAI) is looking to enter the Chip market to prevent value leakage, while simultaneously partnering with Microsoft to fund access to Compute Hardware via Azure cloud credits.
- Meta has no presence in Cloud, but has lots of data and users, so they will seek to push value accrual in those directions. By releasing Llama 3 as an open-source model and ‘throwing-down’ capital on Nvidia chips while developing their own silicon, Meta is encouraging developers and researchers to enhance their Llama model, thus reducing OpenAI’s lead in LLMs, and making Meta’s AI competitive. Any open-source enhancements to Llama will also reduce Meta’s Capex and allow Meta AI to retain users which might otherwise gravitate to closed platforms such as OpenAI. Meta have the largest store of human relations and biggest social graph which should provide a significant advantage in model inference.
- Amazon has a huge cloud business – AWS – and will obviously want value accrual to orientate towards the Cloud. Amazon is developing custom generative AI chips, which will further enhance its AWS AI capabilities while also reducing value leakage to Nvidia for Compute Hardware in it’s AWS data centers.
What is clear, is to compete effectively, the mega caps need to bring together four key elements:
- significant capital for Capex and relationships throughout the compute supply chain
- access to substantial data for training and inference
- skilled personnel for model build and product integration, and
- strong distribution channels to end users.
Layer by layer views on value accrual trends
Not to give the punchline away, but the below is a RAG rating of where I think we currently sit – in the short term – in terms of ‘value accrual’ – by which i mostly mean ‘Free-Cashlow Generation’.

What follows are my views of the key emergent factors and questions investors should be contemplating at each of the 7 layers for longer-term value accrual.
Layer 1: Compute Hardware
One of the things that we see and we’ve said is that the TAM for AI compute is growing extremely quickly. And we see that continuing to be the case in all conversations. We had highlighted a TAM of let’s call it, $400 billion in 2027. I think some people thought that was aggressive at the time. But the overall AI compute needs, as we talk to customers is very, very strong.
AMD CEO, Lisa Su – 30 April 2024 (Earnings call)
To date, money and value has been mostly accruing to those providing the Compute Hardware – i.e. Data Center GPUs. In particular, Nvidia has been the standout winner due to c 92% share of Data Center GPUs (their H100 GPU is the market leader and back-ordered) which power most of the testing and inference of large language models (LLMs).
Nvidia’s Free Cash Flow increased from USD 4bn to USD 27bn per annum over this period, and is trending to USD 54bn in FY25.

❓ The key Compute investment question: when will competitors catch up with Nvidia AI GPUs – bringing down the price of compute?
My View:
An increase in free cash flow from USD 4bn to USD 54 billion brings to mind the famous Jeff Bezos quote: “Your margin is my opportunity” – and true to the quote, the following large companies have all announced they are designing their own silicon for AI: Amazon, Apple, Alphabet, Microsoft, Meta, Tesla, Baidu, IBM and OpenAI.
Nvidia market share of AI Data Center GPUs to reduce from c. 92% now to c. 30% by 2030 (this is a SWAG – Sophisticated Wild-Arse Guess). Reasons include:
- Nvidia does not manufacture – they rely on semi-conductor Fabs such as TSMC to manufacture their chips – and their ‘moat’ lies in the IP of their chip designs. While this IP will be protected in the US and Europe, the US has banned selling AI GPUs to China, meaning GPU IP will not be respected in China. This is likely to lead to faster replication and cheaper AI GPUs coming to market in China and China’s major trade partners.
- AMD claims to be comparable already (although Nvidia disputes this).
- The Large Caps will not allow Nvidia (or AMD) to continue to reap most of the gains from AI. Given the firepower of the trillion dollar market cap companies – Meta alone has announced USD 40bn in CAPEX per annum on Chips! – they should be able to recruit the best GPU design talent
- Google, Apple, Amazon and Meta already have well established silicon design operations. Meta is already using it’s own silicon for inference and also expects to be using it’s own silicon for training by the time Llama 5 is launched
In the longer run TSMC and ASML (which lead in front-end manufacture) – appear to have more durable AI Compute Moats than Nvidia.
Layer 2: Cloud & Data
Hyperscalers
“We will be meaningfully stepping up our CapEx and the majority of that will be to support AWS infrastructure and specifically generative AI efforts…in Q1, we had $14B of capex. We expect that to be the low quarter for the year”
Amazon CFO, Brian Olsavsky, 30 April 2024 (Earnings call)
On balance, the hyperscalers (AWS, GCP, Azure) should all benefit from the trend towards AI – due to more data demand. However, this is not a given – for example, the telecom companies that built the infrastructure (dark fiber etc) which power the internet, were not the main beneficiaries – in fact many went out of business.
In the short run all hyperscalers have had to:
- invest heavily in AI-powered compute enhancements to their platforms (i.e. Nvidia H100 chips)
- offer cloud credits to emerging AI developers and platforms to entice them to use their cloud platforms
… meaning AI driven growth in cloud compute could well have been Free Cash Flow negative for Hyperscalers in this initial innings and could be for some time.
❓ The key Hyperscaler question: Will there be an on-prem infrastructure revival?
My view:
I work for a large organisation – which is both involved in helping companies implement AI solutions, but also looking to leverage AI to improve its own operations. What is very clear is there is significant concern around data security with regards to Cloud providers and AI. Concerns include:
- Companies not wanting AI to be trained on their data for the benefit of competitors (or Cloud providers which also have their own LLMs – e.g. Microsoft Azure + Open AI)
- Security of client data
- Adherence to data privacy regulations – particularly in countries like China
In tandem, for a while there has been a growing view that cloud solutions are not all they are cooked up to be – i.e. often more expensive and lower latency than on-prem.
As such, I think there will be growing demand for on-prem to the detriment of cloud.
Data owners
To address extreme levels of data scraping & system manipulation, we’ve applied the following temporary limits (on reading of posts/day)….
Owner of X, Elon Musk – 2 July 2023 (post on X)
In the early stages LLM developers were able to scrape the internet with impunity for data to train models on. I.e. the data had ‘no value’ ascribed to it. This is changing.
LLMs require a significant amount of data to train effectively. This data encompasses different forms such as: text, images, audio, and more. The exact amount of data needed can vary depending on the specific model architecture, the complexity of the task, and the desired level of performance.
The largest models have 1 trillion + parameters (Meta used 15tn tokens to train Llama 3), meaning multiple terabytes of (multimodal) data are needed. And it’s not just the quantum of the data that matters, but also the data quality. The data needs to be diverse, well-structured, and representative of the task or domain the model is intended to perform.
❓ The key Data owner question: Who has the most valuable data for AI training and inference, and how will they capture this value?
My View:
Reddit alone has agreed $200+ million from AI data licensing contracts over the next three years. I suspect the most valuable data for training and inference is likely to be real time community based sites such as X, Youtube and Reddit.
The normalisation / existence of AI data licensing agreements like Reddit’s will influence other data owning platforms, and result in more legal battles around data scaping making it more expensive for models to be trained.
In tandem, there will also be the uncomfortable questions re who owns the data on youtube etc – as we have seen with the push for ‘Web 3’.
Layer 3: Models
…so there’s multiple ways where open source I think could be helpful for us. One is if people figure out how to run the models more cheaply well we’re going to be spending tens or like a hundred billion dollars or more over time on all this stuff so if we can do that 10% more effectively we’re saving billions or tens of billions of dollars okay that’s probably worth a lot by itself.
CEO of Meta, Mark Zuckerberg – 18 April 2024 (Dwarkesh Podcast)
❓ Key Model layer question (1/4): Will one LLM dominate? Can Open-Source prevail over Closed?
My View
If you look back in time to early 2023, OpenAI appeared to have a huge – seemingly unassailable lead – the quality of their LLM was way ahead of the competition and every enterprise was looking to get access to OpenAI.
As of May 2024 things have reversed dramatically:
- OpenAi’s lead has been cut short. Open Source models such as Llama rank better in certain modalities (e.g. mathematics) and enterprises are not only experimenting with but also deploying multiple models. In fact the only LLM which to my mind has maintained a clear lead across the period is MidJourney for image generation.
I think we’re now heading to a multi-modal world in which the enterprise market will bifurcate:
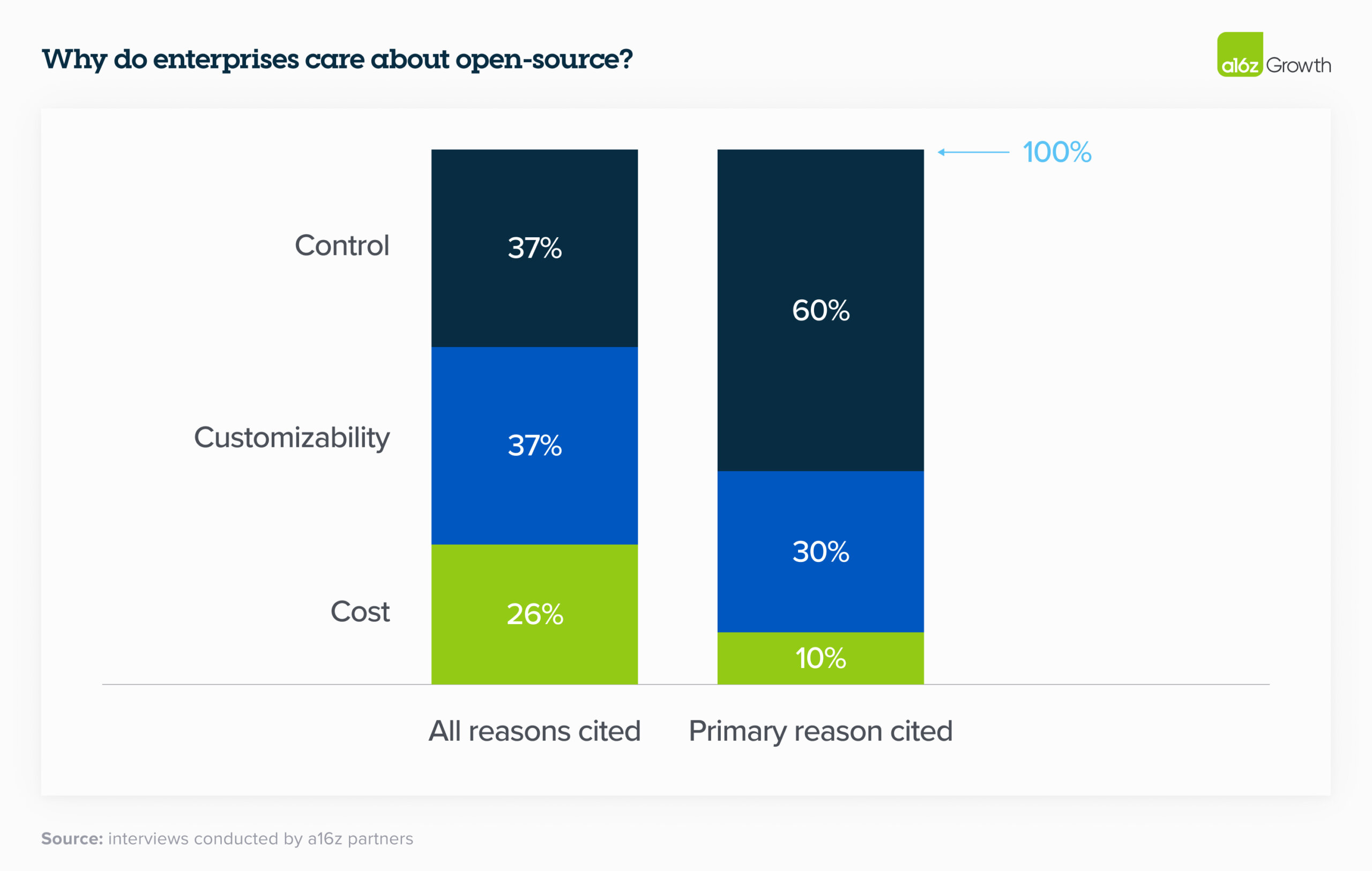
- larger enterprises will look to Open-Source models that they can run On-Prem, thus saving costs and retaining data privacy. There is an upfront infrastructure cost of deploying and maintaining open-source models, but it will be economically worthwhile for businesses with scale. This strategy allows them to tailor solutions based on performance, size, and cost, avoid vendor LLM lock-in, and swiftly leverage advancements as new better LLMs are brought to market.
- conversely, smaller enterprise with lower concerns around data privacy will likely opt for a more Cloud based service from closed source proprietary providers. !https://a16z.com/wp-content/uploads/2024/03/Why-do-enterprises-care-about-open-source_-scaled.jpg
{kind=link}

It’s also clear the different models have different advantages depending on the modality. For example:
- Meta, Google and Grok’s model’s are going to have far more retail user data to train on than OpenAi’s making the more suitable models to act as personal assistants.
- Meanwhile, OpenAI, via the Microsoft partnership will one way or another have far more enterprise access, making it more optimised for business.
….so, there are likely to be multitudes of models which are used for different specific modalities.

❓ Key Model layer question (2/4): Will value accrue to LLM’s or will they be commoditised? If so, how will value be captured?
There are two strategies to build on AI right now. There’s one strategy which is assume the model is not gonna get better. And then you kind of like build all these little things on top of it. There’s another strategy which is build assuming that OpenAI is gonna stay on the same rate of trajectory and the models are gonna keep getting better at the same pace. It would seem to me that 95% of the world should be betting on the latter category. But a lot of the startups have been built in the former category.
CEO of OpenAI, Sam Altman – 15 April 2024 (20VC Podcast)
When we just do our fundamental job, we’re gonna steamroll you. This is it.
My view
From the outset of the AI hype – c. Nov 2022 – the bulk of venture funding has gone into developers of LLMs – Notably OpenAI and Anthropic.

To date almost all LLMs – with the exception of MidJourney – have been cash burning due to compute costs.
From a pure investment standpoint, LLMs appear to be a highly risky bet. Firstly because we appear to be going into a multi-model world – as explained above. But also because the steepness of model depreciation is higher than anything we’ve seen before. For context as of May 2024:
- 1 million tokens of GPT 3.5 Turbo via API currently costs $1.50
- 1 million tokens on GPT 4 Turbo (the ‘best’ model) costs $30.00
- i.e. When GPT 5 is released, you would expect GPT 4 to be priced at current GPT 3.5 levels and GPT 5 to be priced at GPT 4 levels – a 20x decline in LLM value on release of a new model!
Simultaneously the economic model for LLMs is shifting. At one point c. 50% of OpenAI’s revenues came from the $20m a month subscription charge to retail. This doesn’t appear sustainable given Meta and Google are now offering equivalent services for ‘free’.
It’s likely the economics of models will either be (1) Ad-Based (Retail) or (2) API based (Enterprise) or (3) Revenue share basis with cloud providers running proprietary models (Meta already has revenue share agreements with AWS and Azure for Llama).
Distribution is going to be critical, and unless a standalone model has a clear differentiation in quality, my guess is investments in LLMs will not deliver value. The value is not in the model, just like the value in Cloud is not in storage unto itself. The value is in the enterprise relationship and services offered to customers.
As such, it’s going to be increasingly difficult for new closed-sourced entrants to be venture backed because of the size of Capex required and uncertain value accrual. Any new models that comes along, will need to attack a completely different modality to incumbents to get funding.
❓ Key Model layer question (3/4): Are bigger models better?
My view:
The market is moving towards both specialised smaller models and larger models concurrently, each catering to distinct use cases.
As a retail user it’s ‘ok’ to use a chat interface and wait several seconds for a response. But as an enterprise – particularly one looking to obtain inference from millions of tokens at a time, this speed plus the complexity of interacting through chat interfaces is not ok. I.e. Model latency is becoming much more important – which pushes demand to the smaller (less parameter), faster, models. Facebook claim the 8bn parameter version of Llama 2 is almost as powerful as the
It also seems likely that wearables (smart glasses etc) will need a small on-device LLM to provide sufficient latency (the trashing of Humane’s AI Pin has demonstrated that low latency is a fail – see THIS), which can then connect to a larger cloud based LLM under certain circumstances.
❓ Key Model layer question (4/4): How far are we from Artificial General Intelligence (AGI)?
My view:
The biggest downfall of all current models – in terms of getting to AGI – is a lack of ‘memory’. Without memory a model can’t truly interact with you, learn your preferences and become personalised to your needs. This is the area requiring the most development.
It’s not clear to me how memory can be built without having local or unique instance of an LLM with access to all your devices – which for most people would be prohibitively expensive.
Layer 4: APIs / Model Hubs
We all got kind of comfortable with the pace of chat GPT. But if you kind of go away for a second and try one of these smaller models somewhere else and go back to chat GPT, you’ll really have that like, we all have that moment for a bit between dial Up and high speed internet where we maybe had dial up at home still and high speed at work. That’s the feeling that you get when you switch between those two things.
Head of Groq Cloud, Sunny Madra – 29 April 2024 (BG2 Podcast)
❓ Key API / Model Hub layer question: Will value accrue to model-hubs?
My view:
The success of model-hubs is predicated on the success of OpenSource versus Closed models.
From an investment standpoint, Model Hubs and providers of support to developers of Apps/Software using LLMs – seem like fertile ground in terms of risk/reward. They are AI ‘picks and shovels’ and the two standout players presently are Groq and HuggingFace.
Groq provides cloud hosting and API interface into OpenSource models for developers. It has seen rapid take-up in its services leveraging the competitiveness of Llama 3 versus GPT-4.
GPT-4 v Llama 3 performance & price.

Chart showing Groq tokens served over time – March to May 2024

Hugging Face has also become ‘the’ default AI community – the place to go for access to open source code and trouble shooting – and has clearly achieved network effects. At it’s August 2024 funding round it was valued at USD 4.5bn, but is likely far more valuable now, trading off the back of the Llama 3 and Open-Source growth.
Layer 5: Apps / Software
Unlike other enterprise tools for knowledge work like Microsoft Copilot, Perplexity Enterprise Pro is also the only enterprise AI offering that offers all the cutting-edge foundation models in the market in one single product: OpenAI GPT-4, Anthropic Claude Opus, Mistral, and more to come. This gives customers and users choices to explore and customize their experience depending on their use cases.
CEO of Perplexity, Aravind Srinivas – 23 April 2024
Generative AI products take a number of different forms: desktop apps, mobile apps, Figma/Photoshop plugins, Chrome extensions, Discord bots etc. It’s also easy to integrate AI products where users already work, since the UI is generally just a text box – hence CoPilot’s rapid growth. Which of the standalone apps will become standalone companies is unclear — it’s likely that any standout success will be absorbed by incumbents, like Microsoft or Google.
❓ Key Apps / Software layer question: Do standalone AI Apps / Software stand a chance against the big Tech companies and large closed-source LLMs?
My view
The scarcest commodity for most companies, at least at a certain scale, is focus. When a company is a startup, it may be constrained by capital and resources, leading to a singular focus on one idea. As a company grows, it crosses a threshold where maintaining focus becomes crucial.
There are a tonne of different modalities for Gen AI meaning the largest companies will struggle to out compete emerging players in all.
Indeed, players like MidJourney – the King of AI Image generation in my view – controls the end end-to-end model and app and has gotten to $200m in ARR with NO funding.
Also, Perplexity – an (excellent) AI powered Google Search competitor – currently offers (in my opinion) a superior experience to Google and Chat GPT as a search platform. Perplexity is leveraging multiple LLMs – closed and open source – to mitigate the risks of LLM vertical integration / cut-off from leading models. Perplexity has now reached a c. USD 3bn valuation.
Layer 6: Devices
“…With Circle to Search, people can now circle what they see on their Android screens, ask a question about an image or object in a video and get an AI overview with Lens… We have 6 products with more than 2 billion monthly users, including 3 billion Android devices”
Alphabet CEO, Sundar Pichai – 25 April 2024 (earnings call)
❓ Key device layer question: When are Apple going to make their Grand Entrance?
My view
I think Device manufacturers like Apple stand to capture significant value from GenAI.
The biggest surprise in AI to date, may be that Apple has made so few inroads. Their AI voice assistant “Siri” was lunched 14 years ago and remains a side show. Apple also seems to have no meaningful LLM under development. However, given their devices – mobile/iPhone, PC/mac, Ipad, Apple Vision etc will be key interfaces to end users – they still should have a meaningful say. Through devices and the App Store (and Android stores) – Apple and Alphabet have an opportunity to capture 30% take rates on any retail AI subscription revenue (or uptake in subscription apps which implement AI enhancements).
If small LLMs’s continue to show advances in capabilities, it becomes likely that models will run directly on devices, rather than wholly through the cloud. This also benefits leading device manufactures, over cloud providers.
It appears were are also getting closer to autonomous vehicles with Tesla licencing Full Self Driving (FSD) from 2022, with the price falling to $99 a month from April 2024. In April 2024, Tesla also reached agreed with Baidu to offer FSD in China. It seems strange therefore, that Apple just cancelled plans to produce an ‘Apple Car’. It also seems increasingly misguided that Apple decided not to acquire Tesla on the cheap in the 2010s.
Layer 7: Users
Enterprise AI
“I think every business is going to want an AI that represents ‘Their Interests’. They’re not going to want to primarily interact with ‘you’ through an AI that is going to sell their competitors products.”
CEO of Meta, Mark Zuckerberg – 18 April 2024 (Dwarkesh Podcast)
❓ The key user question – enterprise AI: Will all enterprises see bottom line benefits from AI?
My view
In short, no:
- Enterprises in competitive industries will see simple to implement GenAI productivity gains passed on to end customers through lower unit pricing – as these gains will be swiftly copied by competitors
- Only monopolies will be able to capture the bottom line benefit.
This is not to say enterprises should not be actively exploring use cases – if they don’t and competitors do, they’ll see margin declines.
The ‘Alpha’ for companies in competitive industries will come from hard to implement / copy custom AI solutions.
I also feel there are several hurdles that first need to be overcome for scaling generative AI in enterprise. These include:
- a lack of specialised technical talent
- expertise in developing and managing complex computing infrastructures
- ability to capture and structure data effectively to leverage LLMs fully
To address this, foundation model providers will need to partner with professional services providers (i.e. systems implementers) who can support with custom model development. This is a key distribytion channel for large enterprise.
The scarcity of in-house genAI expertise also means that startups offering tools to simplify genAI integration are poised for rapid growth.
Personal AI
❓ The key user question – Personal AI: Is AI going to be as fundamental to people, as going from not having computers to having computers – or the transition to smartphones /Apps ?
My view:
I spend c $100 a month on AI related paid subscriptions. These include:
- OpenAI (GPT 4 access + API Access). I also run the lighter versions of Llama locally on my mac.
- Midjourney (AI image generation)
- Snipd (AI podcast transcripts)
- Adobe Firefly (AI image generation)
- Finchat (AI driven investments analysis)
At present, while i obtain significant benefit from AI, it is not life changing. Part of this is speed, and part is personalisation.
I think the game changing moment will only come when AI becomes uniquely personalised to my needs. For this to happen we will need smaller, more capable models which can run locally on portable devices, and also be given access to (all) my data, recall all my preferences – i.e. have local memory. It feels like we are 5+ years away (this is another SWAG).
Also worth saying that as a user, i’m not tied into any specific AI app yet – i float between versions based on what is the latest and greatest and am always trying new products.
So… Long-term – where will value accrue?
Taking into account the above, the map below is my current take on areas for long-term value accrual.

In short:
- Compute Hardware – I believe the cost of compute will go down. Nvidia is currently enjoying supernormal profits and these will be whittled away by competition. The long-term compute moat belongs to the dominant front-end manufacturers.
- Cloud & Data – Leading data owners will rewarded. Cloud providers will see less benefit than expected due to drive to on-prem AI.
- Models – I think Meta’s actions with open-sourcing Llama means the model layer will not accrue value UNLESS the model providers have direct to user access.
- APIs / Model Hubs – I see this as a fertile area, with high network effects for leading open-source facilitators.
- Apps / Software – distribution remains key. If open-source LLMs remain competitive, the leading App / Software providers will see limited value leakage (to closed source models) and thus benefit.
- Devices – I can see a situation where personalised AI is run locally on-device. This would allow greater value capture for advice manufacturers as they would then control distribution.
- Uses – On the enterprise side, it’s really only companies with monopolies that will reap benefits to their bottom line.
Sources / Borrowed ideas / Further reading / listening
- A16Z – 16 Changes to the Way Enterprises Are Building and Buying Generative AI: https://a16z.com/generative-ai-enterprise-2024/
- A16Z – Who owns the Generative AI platform?
https://a16z.com/who-owns-the-generative-ai-platform/ - Dwakesh Podcast – Mark Zuckerberg – Llama 3, Open Sourcing $10b Models, & Caesar Augustus https://www.dwarkeshpatel.com/p/mark-zuckerberg
- BG2 Pod – AI Models, Data Scaling, Enterprise & Personal AI Ep8. AI Models, Data Scaling, Enterprise & Personal AI | BG2 with Bill Gurley & Brad Gerstner
- 20VC – Sam Altman & Brad LightCap on the Future of Foundational Models – will they be commoditised. https://www.thetwentyminutevc.com/sam-altman-brad-lightcap/